Overview
Casibase is an open-source Domain Knowledge Database & IM & Forum Software powered by ChatGPT.
Casibase features
Front-end and back-end separate architecture, developed by Golang, Casibase supports high concurrency, provides web-based managing UI and supports multiple languages(Chinese, English).
Casibase supports third-party applications login, such as GitHub, Google, QQ, WeChat, etc., and supports the extension of third-party login with plugins.
Based on embedding and prompt engineering for knowledge management, Casibase supports customized embedding methods and language models.
Casibase supports integration with existing systems by db sync, so users can transition to Casibase smoothly.
Casibase supports mainstream databases: MySQL, PostgreSQL, SQL Server, etc., and supports the extension of new databases with plugins.
How it works
Step 0 (Pre-knowledge)
Casibase's knowledge retrieval process is based on Embedding and Prompt engineering, so it is highly recommended that you take a brief look at how Embedding works. An introduction to Embedding.
Step 1 (Importing Knowledge)
To get started with Casibase, users need to follow these steps to import knowledge and create a domain-specific knowledge database:
Configure Storage: In the Casibase dashboard, users should first configure the storage settings. This involves specifying the storage system to be used for storing knowledge-related files, such as documents, images, or any other relevant data. Users can choose from a variety of storage options based on their preferences and requirements.
Upload Files to Storage: Once the storage is set up, users can proceed to upload files containing domain-specific knowledge into the configured storage system. These files can be in various formats, such as text documents, images, or structured data files like CSV or JSON.
Select Embedding Method for Knowledge Generation: After the files are uploaded, users have the option to choose the embedding method for generating knowledge and corresponding vectors. Embeddings are numerical representations of textual or visual content, which facilitate efficient similarity search and data analysis.
How knowledge is embedded?
For textual data: Users can choose from various embedding methods, such as Word2Vec, GloVe, or BERT, to convert the textual knowledge into meaningful vectors.
For visual data: If the uploaded files contain images or visual content, users can select image embedding techniques like CNN-based feature extraction to create representative vectors.
More methods coming soon...
By following these steps, users can populate their domain knowledge database with relevant information and corresponding embeddings, which will be used for effective searching, clustering, and retrieval of knowledge within Casibase. The embedding process allows the system to understand the context and relationships between different pieces of knowledge, enabling more efficient and insightful knowledge management and exploration.
Step 2 (Retrieving Knowledge)
After importing your domain knowledge, Casibase transforms it into vectors and stores these vectors in a vector database. This vector representation enables powerful functions like similarity search and efficient retrieval of related information. You can quickly find relevant data based on context or content, enabling advanced querying and uncovering valuable insights within your domain knowledge.
Step 3 (Building the Prompt)
Casibase performs a similarity search on the stored knowledge vectors to find the closest match to the user's query. Using the search results, it creates a prompt template to frame a specific question for the language model. This ensures accurate and contextually relevant responses, delivering comprehensive answers based on the domain knowledge in Casibase.
Step 4 (Achieving the Goal)
At this stage, using Casibase, you have successfully acquired the knowledge you sought. Through the innovative combination of domain knowledge transformed into vectors and powerful language models like ChatGPT, Casibase provides you with accurate and relevant responses to your inquiries. This enables you to efficiently access and utilize the domain-specific information stored in Casibase, meeting your knowledge requirements with ease.
Step 5 (Optional Fine-tuning)
If you find that the results are not entirely satisfactory, you can try to get better results by doing the following:
Tweaking Language Model Parameters
Asking multiple questions
Optimizing the original files
By utilizing these fine-tuning options, you can improve the efficiency of your knowledge management in Casibase, ensure that the system is better aligned with your goals, and provide more accurate and insightful information.
Other ways to optimize results (may require source code changes):
Updating
EmbeddingResults: Refine the knowledge representation by adjusting the embedding results of your domain knowledge.Modifying
PromptTemplates: By customizing the prompts, you can elicit more precise responses from the language model.Exploring Different
Language Models: Experiment with different models to find the one that best suits your requirements for generating responses.
Online demo
Casibase
- Online Demo (Chat Bot): https://demo.casibase.com
- Online Demo (Admin UI): https://demo-admin.casibase.com
Global admin login:
- Username:
admin - Password:
123
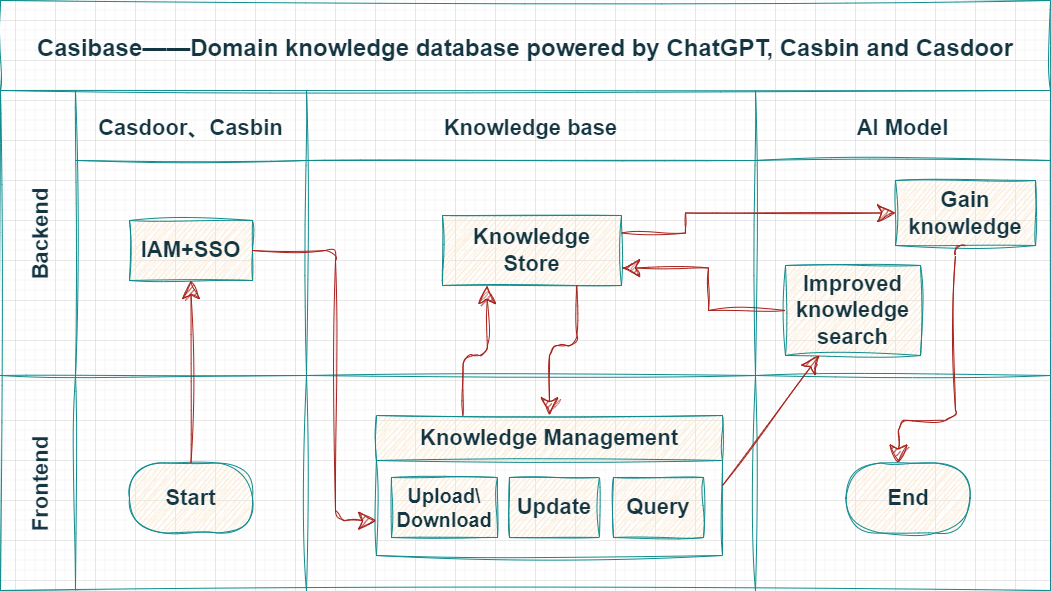
Architecture
Casibase contains 2 parts:
| Name | Description | Language | Source code |
|---|---|---|---|
| Frontend | User interface for the casibase application | JavaScript + React | https://github.com/casibase/casibase/tree/master/web |
| Backend | Server-side logic and API for casibase | Golang + Beego + MySQL | https://github.com/casibase/casibase |
Supported Models
Language Model
| Model | Sub Type | Link |
|---|---|---|
| OpenAI | gpt-4-32k-0613,gpt-4-32k-0314,gpt-4-32k,gpt-4-0613,gpt-4-0314,gpt-4,gpt-3.5-turbo-0613,gpt-3.5-turbo-0301,gpt-3.5-turbo-16k,gpt-3.5-turbo-16k-0613,gpt-3.5-turbo,text-davinci-003,text-davinci-002,text-curie-001,text-babbage-001,text-ada-001,text-davinci-001,davinci-instruct-beta,davinci,curie-instruct-beta,curie,ada,babbage | OpenAI |
| Hugging Face | meta-llama/Llama-2-7b, tiiuae/falcon-180B, bigscience/bloom, gpt2, baichuan-inc/Baichuan2-13B-Chat, THUDM/chatglm2-6b | Hugging Face |
| Claude | claude-2, claude-v1, claude-v1-100k, claude-instant-v1, claude-instant-v1-100k, claude-v1.3, claude-v1.3-100k, claude-v1.2, claude-v1.0, claude-instant-v1.1, claude-instant-v1.1-100k, claude-instant-v1.0 | Claude |
| OpenRouter | google/palm-2-codechat-bison, google/palm-2-chat-bison, openai/gpt-3.5-turbo, openai/gpt-3.5-turbo-16k, openai/gpt-4, openai/gpt-4-32k, anthropic/claude-2, anthropic/claude-instant-v1, meta-llama/llama-2-13b-chat, meta-llama/llama-2-70b-chat, palm-2-codechat-bison, palm-2-chat-bison, gpt-3.5-turbo, gpt-3.5-turbo-16k, gpt-4, gpt-4-32k, claude-2, claude-instant-v1, llama-2-13b-chat, llama-2-70b-chat | OpenRouter |
| Ernie | ERNIE-Bot, ERNIE-Bot-turbo, BLOOMZ-7B, Llama-2 | Ernie |
| iFlytek | spark-v1.5, spark-v2.0 | iFlytek |
| ChatGLM | chatglm2-6b | ChatGLM |
| MiniMax | abab5-chat | MiniMax |
| Local | custom-model | Local Computer |
Embedding Model
| Model | Sub Type | Link |
|---|---|---|
| OpenAI | AdaSimilarity, BabbageSimilarity, CurieSimilarity, DavinciSimilarity, AdaSearchDocument, AdaSearchQuery, BabbageSearchDocument, BabbageSearchQuery, CurieSearchDocument, CurieSearchQuery, DavinciSearchDocument, DavinciSearchQuery, AdaCodeSearchCode, AdaCodeSearchText, BabbageCodeSearchCode, BabbageCodeSearchText, AdaEmbeddingV2 | OpenAI |
| Hugging Face | sentence-transformers/all-MiniLM-L6-v2 | Hugging Face |
| Cohere | embed-english-v2.0, embed-english-light-v2.0, embed-multilingual-v2.0 | Cohere |
| Ernie | default | Ernie |
| Local | custom-embedding | Local Computer |